

Designing the Psyche Spacecraft for the Off-Nominal
![]() By Danielle M. Marsh
By Danielle M. Marsh
An Overview of the Psyche Fault Management Design
Designing, building, testing, and launching an interplanetary spacecraft like Psyche is one of the most complex engineering achievements of our time. We have to design our spacecraft to work perfectly, without fail, on the first try, because unlike systems on the ground, we don’t have a way to repair them after they launch from Earth. Our spacecraft have to be able to detect, respond to, and recover from anything that can go wrong during their missions. This is so complex and so critical to the success of the mission that we have an entire discipline, called fault management, dedicated to designing our spacecraft for any off-nominal event (“nominal,” in space terms, is normal, and “off-nominal” means not as it should be).
I have spent the majority of my career as a fault management engineer, working on many spacecraft, and am excited to explain some of the terminology and concepts behind fault management, using some every day examples!
I’ve always said that to be a good fault management engineer, you have to have a healthy level of paranoia — you have to assume something is going to go wrong! That might sound dire, but it is actually about thinking ahead and being prepared for anything. That’s something most of us are familiar with in our everyday lives, such as when we drive a car.
We can think of a car as a spacecraft and the driver as the ground operator. When designing a car, the engineers design in a series of features to keep the car safe and running. When driving a car, the driver pays attention to a series of observables and takes certain actions to keep the car safe and running. Here are some examples of how the features in a car and the way that it is driven are similar to those on a spacecraft, including if something goes wrong.
When driving a car (see Figure 1 below), there need to be four tires on that car in order for it to work. But there are usually a total of five tires with the car; the four tires that are used to drive, plus a fifth tire that is carried as a spare. In fault management we would call that fifth tire a redundant tire, and since we have five tires and only need four to drive, we would say those tires are five-for-four block redundant. The fact that all four tires could be used in any of the wheel wells is analogous to saying that they are cross-strapped; a driver could put any tire on any other wheel on the car, and it would work the same. This gives the driver flexibility to use any combination of tires in any way, depending on if/how one fails.
Redundancy and cross-strapping are something that we often use on a spacecraft, to ensure that if one component fails, we have alternate configurations to swap to. On Psyche, most of our hardware is redundant and cross-strapped; for example, we have two computers and two imagers, and the imagers are cross-strapped to the computers; this means that any computer can communicate with any imager, so if we lose one we still have at least two configurations that will work.
If a driver runs over a nail that causes a flat tire, we would call that a fault; a fault is an off-nominal “event” that happened (something bad!) that caused a problem with the tire (a flat tire), which is the failure. On a spacecraft, a fault could be a shorted resistor in a piece of electronics that results in a failure of the electronics due to overheating. The fault is the actual event that happens and then the failure is the consequence of that event.
Fortunately, if a driver runs over a nail with their car and gets a flat tire, none of the other tires are damaged; the other three tires are still fine; we call that physical fault containment, meaning that the fault is contained to the one tire without damaging the other tires. We try to design a spacecraft to do the same thing — we try to keep devices separate from each other so that if we have a fault in one device, it doesn’t propagate and cause damage to other devices, thus ensuring fault containment. An example of fault containment on a spacecraft is fusing — if a device has a short circuit, it will blow its fuse and turn off, rather than overheat and damage surrounding components, or draw more power than the spacecraft can provide.
After getting a flat tire, the driver needs to identify the problem and do something about it. We can think of the things that alert a driver that something is wrong while they are driving as error monitors, and the corresponding actions that the driver takes as fault responses. The driver may have a tire pressure monitor, for example. This is an example of a device error monitor — as the tire goes flat, the tire pressure alarm would alert the driver of low pressure, so the driver knows that the tire is having a problem and can stop and immediately fix it. Alternatively, if there is no tire pressure monitor, the driver might notice that the speed of the car changes as the tire loses pressure. This is an example of a functional error monitor — the driver isn’t directly alerted of a problem with the tire, but notices a problem with a function that the tire provides, which is speed.
Because there are many problems with a car that would cause a change in speed, the driver would have to do some investigating to identify the tire as the problem, but will at least know enough to stop driving and pull over. Lastly, if the driver doesn’t have a tire pressure monitor and doesn’t notice a change in speed, at some point the driver will just fail to reach their destination on time. This is an example of a system error monitor — the fault has gone unnoticed and undiagnosed and propagated all the way up the system and precluded the system from meeting its high-level goal, which is to arrive at the destination on time. We have similar error monitors on a spacecraft — some that monitor the health of devices directly (such as the ability of a computer to send and receive data), some that monitor functions (such as pointing stability or temperature maintenance), and others that monitor system level goals (such as completing a turn on time); the spacecraft may not know immediately what causes the problem, but if an error monitor trips the spacecraft at least knows to stop what it is doing, go to a safer state, and attempt recovery actions (similar to a driver “pulling over” and “changing a flat tire”).
If the driver notices something wrong (whether they were alerted by the car or noticed something on their own), they have to take some corrective action in the form of a fault response. The first thing they would probably do is pull over to the side of the road; this is similar to a spacecraft going into safe mode. When a spacecraft goes into safe mode, it stops doing anything that is not critical to safety, and puts itself into a known, stable configuration.
The next thing the driver would do is probably replace the flat tire with the spare tire; this part of the fault response is the corrective action. Corrective action is where the spacecraft attempts to fix the problem, which can include invoking redundancy by doing a device swap to backup hardware. The driver also needs to pull over and fix the problem before something bad happens, such as losing control of the car and hitting something; this is called time to critical effect. In spacecraft fault management, we analyze all of the possible things that can go wrong (faults) on the spacecraft, how long it would take to cause irreversible damage to the hardware or mission, and ensure that the spacecraft can detect and correct faults faster than time to critical effect is reached. If the driver isn’t able to replace the tires themselves, they may have to call AAA and wait for their help; this is similar to a spacecraft entering safe mode and waiting for the ground operators to take some corrective action This can only be done for faults that have a long enough time to critical effect such that it is ok to wait for the ground to take action later, instead of the spacecraft taking action immediately.
Once the flat tire is replaced with the spare, the driver can continue driving, as usage of the spare tire does not affect the other tires; this is called functional fault containment — even though one tire was removed and replaced, none of the other tires had to be removed or replaced. This is enabled by the cross-strapping strategy, which allows any configuration of tires in any of the wheel wells. The spare tire may not work as well in the overall system as the original tire, though, in which case the car may have to be driven slower; this is called graceful degradation — the car is still able to function, but the driver may not get to their destination on time. An example of this on Psyche is that there are two magnetometers needed to meet science requirements; if one fails, we can still meet our science requirements, but it will take longer with only one magnetometer.
If the driver doesn’t want to risk having to stop and pull over altogether, they could drive with run-flat tires instead. This means the car would fail-operational for certain faults, allowing the driver to reach their destination closer to the planned time. We may design in a similar strategy for a spacecraft if there is an event that is time-critical, such as a maneuver or a certain science observation, in which the spacecraft cannot afford to miss the event by being in safe mode. This is more complex than a fail-safe design that just goes to safe mode, because it requires the engineering team to analyze all failure modes and ensure that it is safe enough to continue to operate the spacecraft through them, just as a car manufacturer would have to ensure that it is safe enough to continue to drive on a run-flat tire.
Lastly, once the driver arrives home, they will need to take the car into the shop to get the spare tire replaced with a regular tire. In the meantime, they will need another car to drive, such as a truck that they also have at home. This is called functional redundancy — the device that was damaged is replaced by a different type of device that provides the same function. An example of this on a spacecraft could be using a thruster instead of a reaction wheel to correct a pointing problem.
Once the driver has the spare tire replaced with a new tire, the car is ready to drive normally again! The same thing happens with a spacecraft — once new hardware is in use to replace the failed hardware, the spacecraft can continue with its nominal mission.
When fault management engineers are designing a spacecraft to be able to handle off-nominal scenarios, it can be overwhelming to think of everything that can possibly go wrong, and design the spacecraft to detect and respond to all of them. We can’t think of everything, so we have to design the spacecraft with a series of safety nets to protect for “unknown unknowns” — no matter what goes wrong, the spacecraft will eventually detect a problem and go to safe mode. Low battery voltage is an example safety net on a spacecraft — if the spacecraft detects an unsafe battery voltage, it knows to immediately go to safe mode and wait for ground to take further action, even if it is unknown what caused the problem.
Fault management is a challenging but exciting and rewarding area of spacecraft design! Fault management engineers have to understand how all of the hardware on a spacecraft works, all of the ways it can fail, and how to design the spacecraft to detect those failures and take action to keep itself safe and eventually recover back to nominal operations. Because of this, fault management engineers are always some of the most critical experts on a spacecraft team, because they have a great breadth and depth of understanding of the spacecraft design and operations. Fault management engineers are always the first that are called if something goes wrong, and have been responsible for saving many missions that had problems they didn’t even dream of during their design. One of the most important things in fault management design is to learn from unanticipated problems on the spacecraft and incorporate those lessons into future designs, so that our spacecraft can continue to become more robust and resilient.
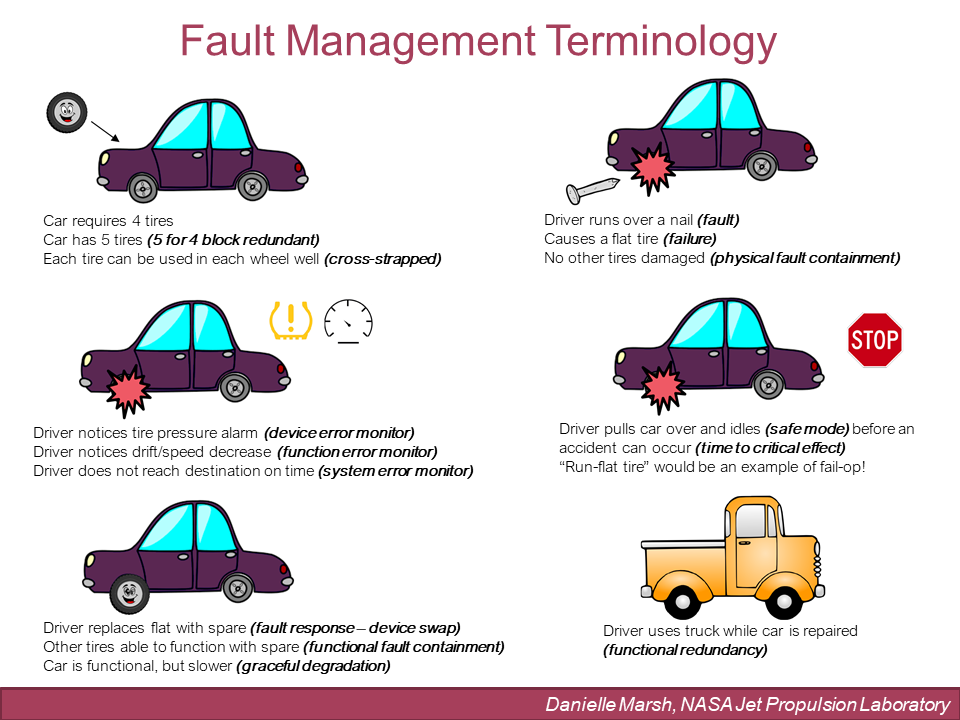
Fault Management Terminology (Credit: Danielle M. Marsh)